Moving 7digital’s catalogue into the cloud
Posted by Michael Okarimia in 7digital, API, Cloud on January 31, 2016
7digital provide a web API platform for it’s customers to discover, stream & download music.  Every request to the public platform first is received by the Gateway API, which then redirects the requests to a dozen or so web applications of which have single responsibility, such as search or payments. These web applications read catalogue data from a database and return it to customers in XML format via HTTP responses.
7digital’s customers are spread around the world yet the API and its data is primarily located in London data centres. This means that latency, resilience and local targeting of content is not optimised for countries like India, where our largest music streaming service is located. In order to reduce latency for customers in Asia, we had the goal to migrate Catalogue Web applications and its corresponding database into an AWS region near the customers. By moving the APIs into the AWS cloud, it became possible to serve a greater volume of traffic by scaling up the number Web application running in parallel. For example, more search servers running in parallel allows for far more searches to be conducted at once.
Breaking down the problem
Cloud migration is such a large task, so we decided to break the work down into smaller units of deliverable features, each of which would provide value to the customer.
The part of the platform which our customers use the most, is the ~/track/details endpoint. It provides the access rights and other details of a given track.
The first part of the migration is to move into AWS this parts of the platform that power this endpoint.
The overall goal is to reduce response time for customers in around the world, particularly in Asia and the USA for all requests for this endpoint.
As a prerequisite it was also required to discover if the Gateway API, which governs access to the 7digital API services, is required to move into the same AWS cloud too.
What is the Gateway API?
All requests to the 7digital API are first received by the Gateway API, which governs access to specific features of the platform.
It’s duties include:
- Identifying the client making the request
- Checking to see if the client has not exceeded their daily request limit
- Ascertaining if the client is allowed to access the service they are requesting
If all the above conditions are met, it will then redirect the request to the appropriate internal Web application which will provide the requested service.
Although Amazon do provide a service similar to the Gateway API, it was soon discovered that their product would not be sufficient to provide an equivalent functionality, so a bespoke version was required.
The first deliverable feature from a customer perspective
The initial goal is to move ~/track/details endpoint with streaming data to AWS, ultimately for a client in India. This can be broken down into the following steps
- Deploy a version of the Gateway API, which can authenticate requests from the public web
- Deploy a portion of the 7digital API into AWS and have it operate in parallel with the existing 7digital API.
- Web applications that provide data regarding tracks in the music catalogue will be moved in the AWS Cloud
- Create a new database used solely for storing catalogue data. This database will be queried by the Web applications that need to fetch track details.
- Deploy the database into AWS with appropriate security and permissions so it can be accessed by 7digital’s web applications
- Populate the catalogue database with the data from London database.
- Keep the catalogue database in the AWS region up to date with new content being ingested in the London data centre.
To make this laundry list of requirements into a even smaller slice of functionality, we decided to use our CDN which sits in front of the Gateway API as part of the experiment to test the APIs in the cloud.
It was possible to redirect a specific url from one customer for one track so it is served from our cloud based infrastructure instead of London data centre based infrastructure.
Only a specific url would be redirected, the remainder of the current API Web traffic would continue to the London datacentre as normal.
This meant a request to the specific url would use the following parts of infrastructure which we successfully deployed into AWS.
The MVP
A stub Gateway API in AWS using nginx, which merely redirected to
A Metadata API
An Availability API
A Catalogue API
A MySQL database which can be accessed by aforementioned APIs
A service to listen for messages containing catalogue data and save it to a MySQL database (Catalogue Persister). This is a bespoke programme which listened for the 7digital formatted JSON messages and saved it into the 7digital specific database schema
A Kafka messaging system hosted on a server in the AWS cloud
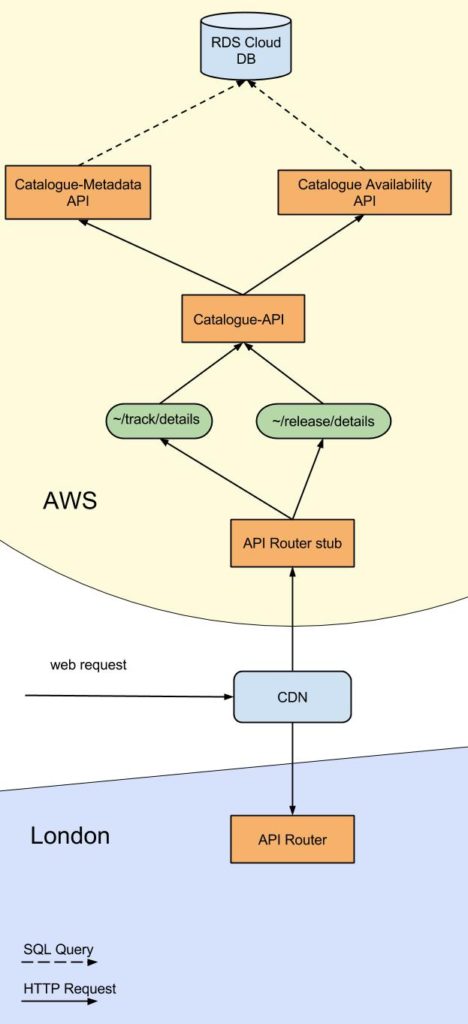
The stub Gateway API was achieved by using nginX software, which could perform most of the functionality the London Gateway API could. The client who is based in India whom we intend to use the AWS hosted version of the platform does not have a usage limit, so the stub of the Gateway API does not need to count requests.
Deploying the Metadata, Availability and Catalogue APIs to the AWS region proved that it was possible to have functioning APIs in the region. They called the MySQL database which we deployed to the same AWS cloud.
The Catalogue Persister service which listened to messages containing catalogue data worked as a proof of concept but was not production ready.
The idea of the persister was that we could send JSON formatted web requests to this service, and it could persist them into the MySQL database in the AWS cloud. However we soon realised that this would make it difficult to track what had been sent to the service and the feature was then abandoned. It did, however, fulfil its initial goal of populating data sent to it from London, but it was superseded by the Kafka messaging approach.
In the London datacentre there would need to be a service which read the data from the London database and send it the AWS region. We used Kafka service as the data integration point between London and the AWS region.
We opted to use a Kafka messaging system instead of the Catalogue Persister because it allows for every message to be logged and stored in chronological sequence; it became easy to replay all of the messages that had been sent. This is important in order to ensure the databases in London and the AWS region are consistent. The Kafka messaging service consisted of:
A server running Kafka software, inside the AWS VPC (Virtual Private Cloud)
A server running cluster management software called Zookeeper, which was to manage the servers running Kafka
A VPC configuration which allowed for the Zookeeper servers to receive requests from the public web and forward those onto the Kafka servers it was managing. The Kafka instances themselves are not accessible from the public web.
In our London Datacentre we created a programme which could read data from our existing shared database and send it to the Kafka service. We called this programme the Catalogue Producer. This was a bespoke programme which read data from our London database and pulled out the data for a single album. It then encoded it into a JSON format, and finally sent it to the Kafka messaging service in the AWS cloud.
This experiment worked as a proof of concept. To make this read for production we were going to change this programme so it could read the entire catalogue from the London database, convert it into many JSON formatted messages, and send those into the Kafka instance in the AWS cloud. Those messages could then be received and saved into the catalogue database in the AWS cloud.
It was proposed that we create a service in AWS which can read messages from Kafka an persist them into the AWS database, thus allowing data from the London database to be transmitted into the cloud database. However this was not started in 2015, and thus uncertainty #7 remained an open question.
Once the data was in the catalogue AWS cloud database, the portion of the 7digital API that was hosted in the AWS region could then display the data stored, thus fulfilling the project goals.
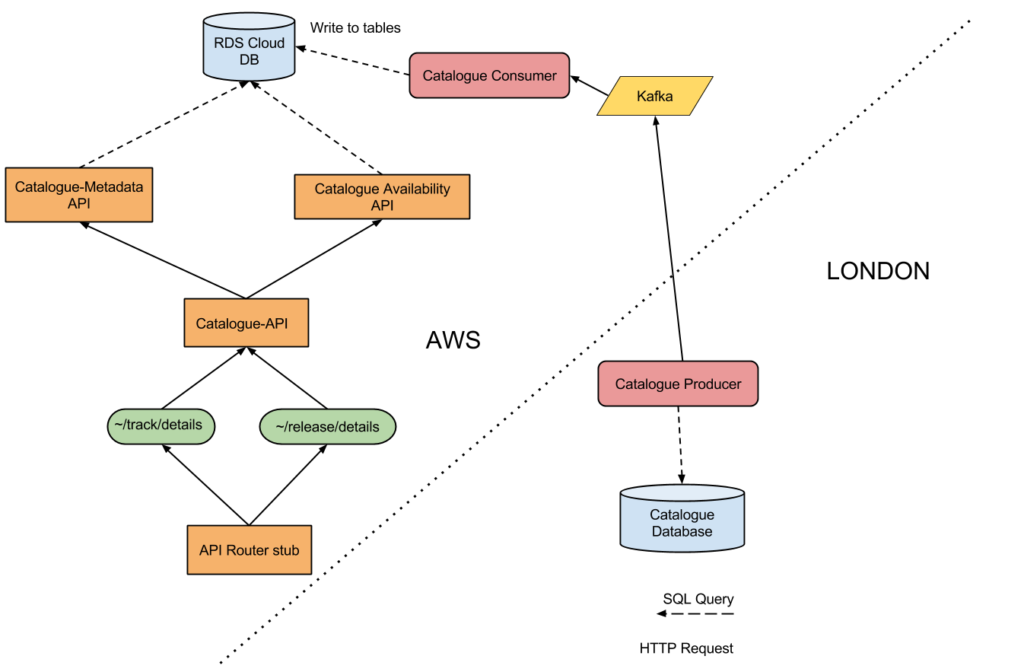
Summary of Outcomes
Catalogue API and supporting Metadata and Availability API’s deployed to an AWS region. A MySQL database was deployed there too, which the correct security access settings, so the three APIs could query that database. A stub of a Gateway API which could redirect external web requests to the internal Catalogue API was created. This allowed for the Catalogue API to be accessible via the public Web. We then made a change to 7digital’s CDN provider, Fastly, to allow a specific request to be redirected to the AWS version of the Catalogue API, instead of the London based API.
We also set up a Kafka instance in the AWS region, which was to act as a place where messages containing catalogue data were to be sent. This Kafka instance  only accepted traffic from the 7digital London office.
A service which could read a single track from the existing London database and push a message containing the track data to the Kafka instance was also created. This was called the Catalogue Producer. It’s goal was to send catalogue updates to the AWS database via the Kafka service.
Goal of moving the Gateway APIÂ was partially achieved when the scope of the functionality was reduced, but questions remain surrounding authentication and request limiting.
Although it was possible to serve live traffic, there remains questions of how effectively the platform would work. A/B testing would help use see what levels of traffic the new infrastructure could handle
The challenge of moving catalogue data from London to the AWS database was partially solved, whereby it was shown that is is possible to transmit a message containing the data to represent a album into a Kafka messaging service in an AWS cloud. This project served as an useful proof of concept and starting point for the migration of 7digital’s API into an AWS region.
Fixing 7digital’s Music Search, Part Three: The Virtuous Circle of Success
Posted by Michael Okarimia in 7digital, API, Automation, Lucene, search, SOLR on September 25, 2015
This is the third and final post in a series about how we improved the catalogue search at 7digital. You can start at Part one, or skip to Part two
We succeeded in improving 7digital’s music search results accuracy by using customer feedback, application monitoring and metrics, and continuous delivery.
A major factor in allowing us to complete the task was our Continuous Delivery pipeline, comprised of an automated Teamcity deployment process and a test environment which was effectively identical to our production environment.
From the git push of our tests and code, it took 15 minutes to deploy changes to Production. The work flow was automated in the test environment and then finally deployed to production with a human clicking the deploy to PROD button.
From the push, code was compiled, unit and integration tests were run, the application was deployed to test environment automatically and then acceptance tests were run on the test environment.
We would routinely then deploy the new code to only one server in the cluster as a “Canary release” a.k.a “canary deploy” and monitor that server for 10 minutes to ensure it had not adversely affected performance. If the change was for the worse we could immediately roll back the change and deploy the previous version of the code on the “canary server”.
Otherwise after monitoring performance, we would deploy the new code to the remaining production servers, and let our users enjoy the new improvement.
The rapid feedback allowed for multiple deploys to production to be made a day, with low risks of errors, since we practised Test Driven Development.
Beyond the response time, we wanted to analyse the accuracy of the search results themselves on production. To that end we used our Logging Platform built on the ELK stack (Elasticsearch, Logstash, Kibana) to see what the most common search results were, what number of queries were yielding 10 or fewer matching results, all in near real time.
We called this Kibana dashboard our Search quality dashboard.
We measured success by the reduction of query time and improved accuracy of results. As part of the acceptance tests we created acceptance tests which tested the search results for a list of given terms.
SOLR & Lucene search in a nutshell
Lucene is a full text search engine.
A document is sent to Lucene. Lucene will look at the document, analyse it’s fields, convert the text in the fields into terms (a process called tokenising) and store those terms with the document into an index.
An index can contain millions of documents.
This process adding documents to an index is called indexing.
Search terms can be sent to a index to query it. Lucene will return any documents that have terms matching the search term.
SOLR is a web service which wraps around a instance of Lucene. One can send documents to SOLR via HTTP and it will add those into a Lucene index. Queries can also be sent over HTTP to the Lucene index via SOLR and SOLR will return the search results via HTTP too. The index can be administered via HTTP requests sent to the SOLR web service.
Continuously Delivering Search Improvements
For our track & release indexes, creating a new index of the music catalogue on a regular basis meant we could take advantage of the index time features that SOLR offers.
Searches for track and releases used both SOLR and the internal Web API.
The catalogue Web API can accept up to 500 release or track IDs in a single GET request and return the metadata for all of them in a single response. The catalogue API would only fetch the content if the IDs were valid, but would also filter those results based on the complex licensing agreements 7digital have with both the music labels and 7digital’s clients.
This new smaller search index has meant:
- we could create a brand new index within an hour, meaning up to date data (previously, index creation took several days);
- have longer document cache and filter cache durations, which would only be purge at the next full index every 12 hours, this helped performance;
- it was quicker to reflect catalogue updates, as the track details were served from the SQL database which could be updated very rapidly.
Prior to the start of the redesign of 7digital’s catalogue search service, clients had complained that the accuracy of the search results for track and release searches was not useful.
After gathering feed back from users, both internal and external to 7digital, we came up with a list of specific search terms and the expected results, none of which the search algorithm was returned.
We sought to remedy this. This was achieved by modification of the Lucene’s term frequency weighting in the similarity algorithm.
It transpired that to meet our customers expectations we would have to delve into the inner workings of SOLR and Lucene to override the default search behaviour.
Search quality dashboard enabled us to view how search terms were received from clients and how a SOLR query was built and then sent to our SOLR servers.
Filtering out matching yet inconvenient results
Some labels deliberately publish tribute, sound-alike and karaoke tracks with very similar names to popular tracks, in the hope that some customers mistakenly purchase them. These tracks are then ingested into our platform, and 7digital’s contract with those labels means we are obliged to make them available. At the same time, consumers of our search services complain that the karaoke and sound-alike artists are returning in the search results above the genuine artists, mostly because of the repeated keywords in their track and release titles.
In order to satisfy both parties, we decided to override default Lucene implementation of search and exclude tracks, releases and artists that contained certain words in their titles, unless the user specifically entered them in as search term. For example, searching for “We are the champions†now returns the tracks by the band Queen, which is what customers expect. To achieve this we tweaked the search algorithm so all searches by default it will purposefully exclude tracks with the text “tribute to†anywhere in their textual description, be it the track title, track version name, release title, release version name or artist name.
The results look like this: https://www.7digital.com/search/track?q=we%20are%20the%20champions%20queen
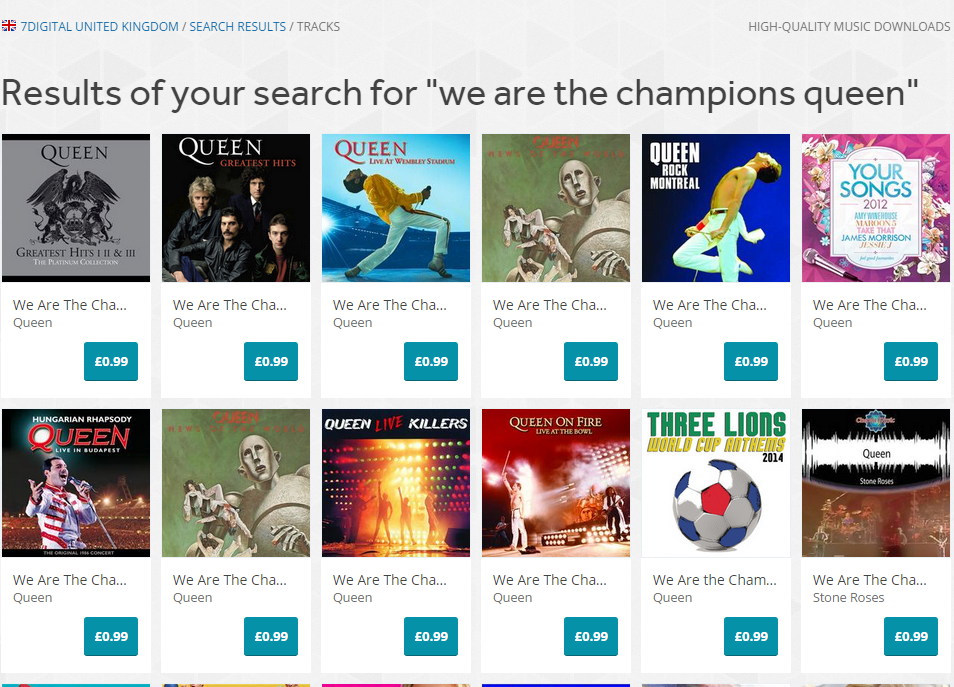
Filtering out tribute acts
Prior to the change, all tribute acts would appear in the search results above tracks by the band Queen. To allow tribute acts to still be found, the exclusion rule will not apply if you include the term “tribute to†in your search terms, as evidenced by the results here: https://www.7digital.com/search/track?q=we%20are%20the%20champions%20tribute%20to%20queen
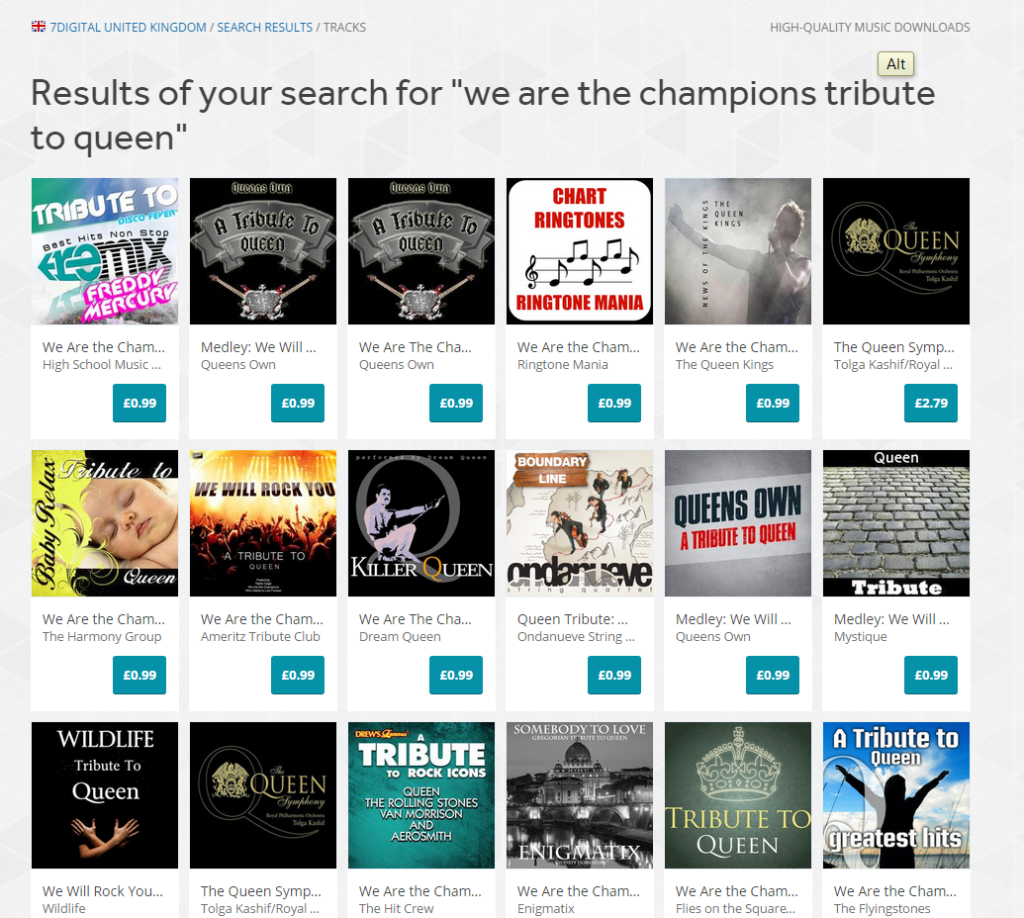
Tribute releases were incorrectly higher in search results
Other music labels send 7digital a sound-alike recording of a popular track, and name it so it’s release title and track tile duplicate the title of a well known track. By ranking results by popularity, the releases with deliberately misleading titles would rank lower in the search results as our customers tended identify the originals and play and purchase them more frequently that the sound-alike releases. This would mean those releases would be calculated to become more popular and at the next index rebuild time would find themselves higher in the search results, thus inducing a virtuous circle.
Tailoring Lucene for music search
Lucene is a capable search engine which specialises in fast full text searches, however the documents it is designed to search across work best when they are paragraph length containing natural prose, such as newspaper articles. The documents that 7digital add to Lucene are models of the metadata of a music track in our catalogue.
Standard implementation of Lucene will give documents containing the same repeated terms a higher scoring match than those that contain a single match. This is means when using the search term: “Michael†results such as “The Best of Michael Jackson†by “Michael Jacksonâ€, will score higher than “Thriller†by “Michael Jackson†because the term “Michael Jackson†is repeated in the first document, but not the second. We solved this issue by overriding the default similarity algorithm in Lucene for our installation of SOLR.
With regard to matching text values this makes sense, but for a music search we want to factor in popularity of our releases based on sales and streams of it’s tracks.
Ignoring popularity leads to a poor user experience; since “Best of Michael Jackson†release is ranked as the first result, despite being much less popular than “Thriller†which is ranked lower in the search results.
Indexed Terms and Stored Terms
The smaller index size meant that we could add fields to each document which weren’t displayed (called stored fields) but could be matched against a search term or influence the search results (called indexed fields). This meant index time features such as filter factories could be applied to certain indexed fields in a document to create terms which would be matched to the client’s search term https://wiki.apache.org/solr/AnalyzersTokenizersTokenFilters
These terms would not be returned in a search result, but were likely to match a user’s search term.
We also added functionality to support auto-complete style searches. Partial search terms could be sent to SOLR and by using Edge n grams filters at index time to create terms we achieved a simple prefix search.
For a document, a shingled and prefix field was added along with fields which were analysed by the standard filters. At query time we could alter the weighting of how important a field was to be when generating the SOLR query.
One useful tokeniser was the Text shingling filter which when applied to track titles such as “How Big, How Blue, How Beautiful” by Florence + The Machine.
The terms generated would include “How Big”, “How Blue”, “How Beautiful”. Search terms sent to Lucene including any of those tokens would match the track document
In addition to tweaking the search algorithm we also could make certain search terms synonymous with others. We created a Git repository on Github with public access; anyone can submit to us a pull request to add new synonyms for our search platform. We can choose to accept the search synonym to our platform and the change will be effected on our search API within 12 hours of our acceptance of change. Repository is here: https://github.com/7digital/synonym-list
Conclusion
Given that there are 40 million tracks in the 7digital catalogue, there is almost endless scope for tweaking the search results. Improving the search algorithms in Lucene to maximise customer happiness was an engaging experience, with the talented team at 7digital I found it to be a highly enjoyable time. We certainly left the music search in a better state than we found it.
And of course, we could upgrade it to Elasticsearch for even more features….
RideLondon 2015
Posted by Michael Okarimia in charity on August 3, 2015

On Sunday 2nd August I cycled 100 miles through London & the Surrey Hills as part of the Prudential RideLondon, and I’m raising money for the charity Leukaemia And Lymphoma Unit, based in UCL Hospital in Euston. (LALU)

This the second time I’ve done a fund raiser for any charity, the last one was for LALU five years ago!
My connection with LALU is that they have been helping my uncle battle Leukaemia for the past decade.This charity have been supporting his out-patient care whilst he is undergoing chemotherapy; they provide bursaries for the fantastic post-grad Leukaemia nurses who work there.
Here’s the link that will let you donate, all proceeds will go to the charity:
http://uk.virginmoneygiving.com/MichaelOkarimia-Ride100-2015
I finished the ride in 5 hours 50 minutes, well under my target of 7 hours 30 minutes! It was an amazing day and unforgettable experience to ride along closed roads, particularly those in central London. At the finish I relaxed with my friends and family in Green Park.
Here’s the official event timings I finished; in 5 hours and 50 minutes
Here’s my route with the all the juicy cycle statistics: https://connect.garmin.com/modern/activity/852419031
The weather conditions were perfect, sunny and with very little wind. I had to cycle from my flat in south east London to the beginning, and I took advantage of the fact that the Blackwall Tunnel was closed off to traffic and only RideLondon participants were allowed to use it. Free wheeling down there from Greenwich north bound in a empty tunnel was incredible; and I hadn’t even started the ride by that point!

RideLondon 2015 start point in the Olympic Park in Stratford
At the northern end of the Blackwall Tunnel I was confronted with the sight of hundreds of cyclists riding along the course towards central London. I mistakenly joined them and rode along for about half a mile before realising they weren’t heading to the start point in Stratford, so I turned around and eventually found my correct destination.

RideLondon 2015 start point
The start point was the Olympic Park in Stratford, and the route began with us riding down the A12 which was closed off to traffic. Zooming along three lane highways and through underpasses like the Limehouse Link and Hyde Park Corner underpass were such an adrenaline rush!

At Kingston the outbound and inbound routes ran along side each other on the same road; here I spotted some of the fast riders who had left a few hours ahead of me, rushing into central London.

Druid’s Head Pub, Kingston

The famous Surrey Hills were beautiful and rolling along it’s narrow, leafy country lanes packed with hundreds of cyclists called for careful attention to be paid. After a 20 minute stop atop Boxhill for some well deserved cake made by the villagers of Boxhill, I continued again.

The numbers of riders thinned out somewhat and I was able to pick up the pace, weaving though the slower riders on the largely downhill sections back to central London. Heading back through Kingston, I think I spotted some of the professionals heading back to the Surrey Hills for RideLondon Classic; famous riders such as Bradley Wiggins and Mark Cavendish were amongst their number.
Here I am crossing Putney Bridge, with only seven miles left till the finish!
The last 30 or so miles were along dual carriageways for large stretches which were closed in both directions; having six lanes to ride along was a very rare opportunity so I made the most of it by cycling on the wrong side of the A-Roads whenever I could and soaking in the views.


My friends caught some video footage of me on the final sprint finish along The Mall!
I didn’t notice them until I had already passed, and I didn’t want to stop at that point!
Of the 25,000 entrants, I was in the last few hundred participants to depart, with a departure time of 08:51. Some of my friends had left at around 06:30 so were in the earlier waves of riders. It turns out I had underestimated my average pace when I filled in the form to enter the sportive with rather unambitious eight and a half hours completion time. This spent most of ride over taking most of the cyclists around me, since the faster groups had left earlier. Unlike when one is running overtaking other participants requires quite a lot of care and there is a risk of a crash. Thankfully I avoided that and took my time.
Once past the finish line I took an obligatory selfie:

Over the finish in Buckingham Palace
I couldn’t have done it with out the help of my friends who I trained with, here we are at the top of Boxhill:

Training at Boxhill with my friends
My friends who also rode the course had finished a few hours before me; they stuck around as we had a picnic in Green Park:

My friends also completed the ride!
It was a fantastic experience and I certainly hope to be able to cycle in the RideLondon 2016 next year!

At the finish line in Green Park
Bonus video footage of the ride by my friend Dave on his GoPro: